Настройка кластера Proxmox VE
-
 Михаил
Михаил
- 12 мин. на прочтение
- 1310
- 20 Jun 2022
- 20 Jun 2022
В данной инструкции мы сначала соберем кластер Proxmox для управления всеми хостами виртуализации из единой консоли, а затем — кластер высокой доступности (HA или отказоустойчивый). В нашем примере мы будем работать с 2 серверами — pve и pve1.
Мы не станем уделять внимание процессу установки Proxmox VE, а также настройки сети и других функций данного гипервизора — все это можно прочитать в пошаговой инструкции Установка и настройка Proxmox VE.
Подготовка нод кластера
Серверы должны иметь возможность обращения друг к другу по их серверным именам. В продуктивной среде лучше всего для этого создать соответствующие записи в DNS. В тестовой можно отредактировать файлы hosts. В Proxmox это можно сделать в консоли управления — устанавливаем курсор на сервере - переходим в Система - Hosts - добавляем все серверы, которые будут включены в состав кластера:
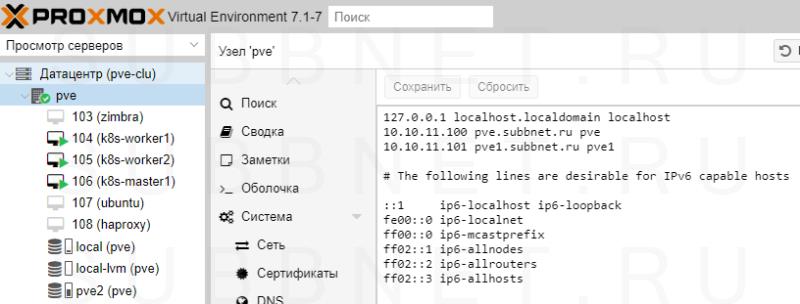
* в данном примере у нас в hosts занесены наши два сервера Proxmox, из которых мы будем собирать кластер.
Настройка кластера
Построение кластерной системы выполняется в 2 этапа — сначала мы создаем кластер на любой из нод, затем присоединяем к данному кластеру остальные узлы.
Создание кластера
Переходим в панель управления Proxmox на любой их нод кластера. Устанавливаем курсов на Датацентр - кликаем по Кластер - Создать кластер:
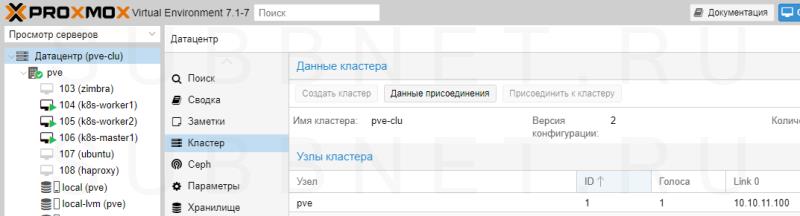
Для создания кластера нам нужно задать его имя и, желательно, выбрать IP-адрес интерфейса, на котором узел кластера будет работать:

... кликаем Создать — процесс не должен занять много времени. В итоге, мы должны увидеть «TASK OK»:

Присоединение ноды к кластеру
На первой ноде, где создали кластер, в том же окне станет активна кнопка Данные присоединения — кликаем по ней:

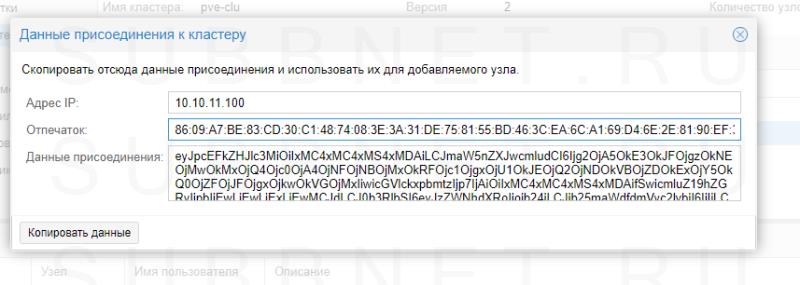
В открывшемся окне копируем данные присоединения:

Теперь переходим в панель управления нодой, которую хотим присоединить к кластеру. Переходим в Датацентр - Кластер - кликаем по Присоединить к кластеру:

В поле «Данные» вставляем данные присоединения, которые мы скопировали с первой ноды — поля «Адрес сервера» и «Отпечаток заполняться автоматически». Заполняем пароль пользователя root первой ноды и кликаем Присоединение:
Присоединение также не должно занять много времени. Ждем несколько минут для завершения репликации всех настроек. Кластер готов к работе — при подключении к любой из нод мы будем подключаться к кластеру:
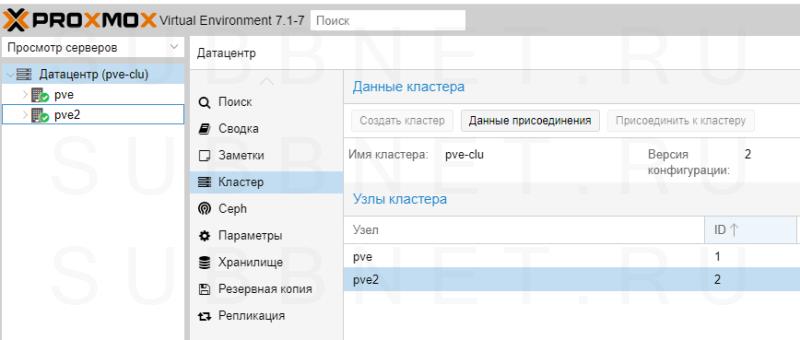
Готово. Данный кластер можно использовать для централизованного управления хостами Proxmox.
Посмотреть статус работы кластера можно командой в SSH:
pvecm status
Отказоустойчивый кластер
Настроим автоматический перезапуск виртуальных машин на рабочих нодах, если выйдет из строя сервер.
Для настройки отказоустойчивости (High Availability или HA) нам нужно:
- Минимум 3 ноды в кластере. Сам кластер может состоять из двух нод и более, но для точного определения живых/не живых узлов нужно большинство голосов (кворумов), то есть на стороне рабочих нод должно быть больше одного голоса. Это необходимо для того, чтобы избежать ситуации 2-я активными узлами, когда связь между серверами прерывается и каждый из них считает себя единственным рабочим и начинает запускать у себя все виртуальные машины. Именно по этой причине HA требует 3 узла и выше.
- Общее хранилище для виртуальных машин. Все ноды кластера должны быть подключены к общей системе хранения данных — это может быть СХД, подключенная по FC или iSCSI, NFS или распределенное хранилище Ceph или GlusterFS.
1. Подготовка кластера
Процесс добавления 3-о узла аналогичен процессу, описанному выше — на одной из нод, уже работающей в кластере, мы копируем данные присоединения; в панели управления третьего сервера переходим к настройке кластера и присоединяем узел.
2. Добавление хранилища
Подробное описание процесса настройки самого хранилища выходит за рамки данной инструкции. В данном примере мы разберем пример и использованием СХД, подключенное по iSCSI.
Если наша СХД настроена на проверку инициаторов, на каждой ноде смотрим командой:
cat /etc/iscsi/initiatorname.iscsi
... IQN инициаторов. Пример ответа:
...
InitiatorName=iqn.1993-08.org.debian:01:4640b8a1c6f
* где iqn.1993-08.org.debian:01:4640b8a1c6f — IQN, который нужно добавить в настройках СХД.
После настройки СХД, в панели управления Proxmox переходим в Датацентр - Хранилище. Кликаем Добавить и выбираем тип (в нашем случае, iSCSI):

В открывшемся окне указываем настройки для подключения к хранилке:

* где ID — произвольный идентификатор для удобства; Portal — адрес, по которому iSCSI отдает диски; Target — идентификатор таргета, по которому СХД отдает нужный нам LUN.
Нажимаем добавить, немного ждем — на всех хостах кластера должно появиться хранилище с указанным идентификатором. Чтобы использовать его для хранения виртуальных машин, еще раз добавляем хранилище, только выбираем LVM:

Задаем настройки для тома LVM:

* где было настроено:
- ID — произвольный идентификатор. Будет служить как имя хранилища.
- Основное хранилище — выбираем добавленное устройство iSCSI.
- Основное том — выбираем LUN, который анонсируется таргетом.
- Группа томов — указываем название для группы томов. В данном примере указано таким же, как ID.
- Общедоступно — ставим галочку, чтобы устройство было доступно для всех нод нашего кластера.
Нажимаем Добавить — мы должны увидеть новое устройство для хранения виртуальных машин.
Для продолжения настройки отказоустойчивого кластера создаем виртуальную машину на общем хранилище.
3. Настройка отказоустойчивости
Создание группы
Для начала, определяется с необходимостью групп. Они нужны в случае, если у нас в кластере много серверов, но мы хотим перемещать виртуальную машину между определенными нодами. Если нам нужны группы, переходим в Датацентр - HA - Группы. Кликаем по кнопке Создать:

Вносим настройки для группы и выбираем галочками участников группы:

* где:
- ID — название для группы.
- restricted — определяет жесткое требование перемещения виртуальной машины внутри группы. Если в составе группы не окажется рабочих серверов, то виртуальная машина будет выключена.
- nofailback — в случае восстановления ноды, виртуальная машина не будет на нее возвращена, если галочка установлена.
Также мы можем задать приоритеты для серверов, если отдаем каким-то из них предпочтение.
Нажимаем OK — группа должна появиться в общем списке.
Настраиваем отказоустойчивость для виртуальной машины
Переходим в Датацентр - HA. Кликаем по кнопке Добавить:

В открывшемся окне выбираем виртуальную машину и группу:

... и нажимаем Добавить.
4. Проверка отказоустойчивости
После выполнения всех действий, необходимо проверить, что наша отказоустойчивость работает. Для чистоты эксперимента, можно выключиться сервер, на котором создана виртуальная машина, добавленная в HA.
Важно учесть, что перезагрузка ноды не приведет к перемещению виртуальной машины. В данном случае кластер отправляет сигнал, что он скоро будет доступен, а ресурсы, добавленные в HA останутся на своих местах.
Для выключения ноды можно ввести команду:
systemctl poweroff
Виртуальная машина должна переместиться в течение 1 - 2 минут.
Ручное перемещение виртуальной машины
Представим ситуацию, что у нас произошел сбой одного из узлов кластера, но при этом виртуальная машина не переехала на рабочую ноду. Например, если сервер был отправлен в перезагрузку, но не смог корректно загрузиться. В консоли управления нет возможности мигрировать виртуалку с неработающего сервера. Поэтому нам понадобиться командная строка.
И так, открываем SSH-консоль сервера, на любой работающем сервере Proxmox. Переходим в каталог qemu-server той ноды, которая не работает:
cd /etc/pve/nodes/pve1/qemu-server
* мы предполагаем, что у нас вышел из строя сервер pve1.
Смотрим содержимое каталога:
ls
Мы должны увидеть конфигурационные файлы запущенных виртуальных машин, например:
100.conf
* в нашем примере у нас запущена только одна виртуальная машина с идентификатором 100.
mv 100.conf ../../pve2/qemu-server/
* где pve2 — имя второй ноды, на которой мы запустим виртуальный сервер.
Командой:
qm list
... проверяем, что виртуальная машина появилась в системе. В противном случае, перезапускаем службы:
systemctl restart pvestatd
systemctl restart pvedaemon
systemctl restart pve-cluster
Сбрасываем состояние для HA:
ha-manager set vm:100 --state disabled
ha-manager set vm:100 --state started
* в данном примере мы сбросили состояние для виртуальной машины с идентификатором 100. Если это не сделать, то при запуске виртуалки ничего не будет происходить.
После виртуальную машину можно запустить:
qm start 100
Репликация виртуальных машин
Если у нас нет общего дискового хранилища, мы можем настроить репликацию виртуальных машин между нодами. В таком случае мы получим, относительно, отказоустойчивую среду — в случае сбоя, у нас будет второй сервер, на котором есть аналогичный набор виртуальных машин.
Настройка ZFS
Репликация может выполняться только на тома ZFS. Подробная работа с данной файловой системой выходит за рамки данной инструкции, однако, мы разберем основные команды, с помощью которых можно создать необходимы том.
Пул ZFS необходимо создавать из командной строки, например:
zpool create -f zpool1 /dev/sdc
* в данном примере мы создадим пул с названием zpool1 из диска /dev/sdc.
Теперь открываем панель управления Proxmox. Переходим в Датацентр - Хранилище - ZFS:

Задаем настройки для создания хранилища из созданного ранее пула ZFS:

* в данном примере мы создаем хранилище из пула zpool1; название для хранилище задаем zfs-pool, также ставим галочку Дисковое резервирование. Остальные настройки оставляем по умолчанию.
После этого мы должны либо перенести виртуальную машину на хранилище ZFS, либо создать в нем новую машину.
Настройка репликации
Переходим к хосту, где находится виртуальная машина, для которой мы хотим настроить клонирование (она должна также находится на хранилище ZFS) - Репликация:

Задаем настройки для репликации виртуальной машины:

* в данном примере мы указываем системе проверять и реплицировать изменения каждые 15 минут для виртуальной машины с идентификатором 100. Репликация должна проводиться на сервер pve2.
Нажимаем Создать — теперь ждем репликации по расписанию или форсируем событие, кликнув по Запустить сейчас:

Удаление ноды из кластера
Удаление узла из рабочего кластера выполняется из командной строки. Список всех нод можно увидеть командой:
pvecm nodes
Мы увидим, примерно, следующее:
Membership information
----------------------
Nodeid Votes Name
1 1 pve1 (local)
2 1 pve2
3 1 pve3* где pve1, pve2, pve3 — узлы кластера; local указываем на ноду, с которой мы выполняем команду pvecm.
Для удаления узла, например, pve2 вводим:
pvecm delnode pve2
Ждем немного времени, пока не пройдет репликация. В консоли управления Proxmox удаленный сервер должен пропасть
Удаление кластера
Рассмотрим процесс удаления нод из кластера и самого кластера. Данные действия не могут быть выполнены из веб-консоли — все операции делаем в командной строке.
Подключаемся по SSH к одной из нод кластера. Смотрим все узлы, которые присоединены к нему:
pvecm nodes
Мы получим список нод — удалим все, кроме локальной, например:
pvecm delnode pve2
pvecm delnode pve3
* в данном примере мы удалили ноды pve2 и pve3.
Необходимо подождать, минут 5, чтобы прошла репликация между нодами. После останавливаем следующие службы:
systemctl stop pvestatd pvedaemon pve-cluster corosync
Подключаемся к базе sqlite для кластера PVE:
sqlite3 /var/lib/pve-cluster/config.db
Удаляем из таблицы tree все записи, поле name в которых равно corosync.conf:
> DELETE FROM tree WHERE name = 'corosync.conf';
Отключаемся от базы:
> .quit
Удаляем файл блокировки:
rm -f /var/lib/pve-cluster/.pmxcfs.lockfileУдаляем файлы, имеющие отношение к настройке кластера:
rm /etc/pve/corosync.conf
rm /etc/corosync/*
rm /var/lib/corosync/*Запускаем ранее погашенные службы:
systemctl start pvestatd pvedaemon pve-cluster corosyncКластер удален.
Переписать образы с одного на другой
scp -rC root@10.10.11.100:/var/lib/pve2/template/iso/ /var/lib/pve2/template/iso/
Скрипт для переноса новых BackupОВ на вторую ноду.
#!/bin/bash
for i in $(find /var/lib/pve2/dump -type f -ctime 0)
do
echo $i
scp -r $i root@10.10.11.101:/var/lib/pve2/dump/
done